Deep dive into NVIDIA Blackwell Benchmarks — where does the 4x training and 30x inference performance gain, and 25x reduction in energy usage come from?

I’ve been trying to write this blog post since the announcements at GTC, and was planning to publish it as a story for The New Stack, but I keep getting stuck on things that don’t make sense to me, so I’m going to put it out there as it is on Medium, and if I get any feedback pointing out where I’m wrong or missing something, I can update it easily.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers don’t make sense based on a simplistic view of the technology changes. The benchmarks are documented in the Blackwell Architecture Technical Brief and some screenshots of the GTC keynote, and I’ll break those out and try to explain what’s really going on from a “benchmarketing” approach. The TL;DR is that the benchmarks are comparing large configurations separated by two generations of technology development, some of the non-obvious speedup comes from a move to a memory centric architecture, and from my viewpoint the energy savings are good but not as big as claimed.
There are three generations of GPUs that are relevant to this comparison. The Hopper H100 was announced in 2022 and is the current volume product that people are using, so that is used as the baseline for comparison. The Grace Hopper GH200 was announced in 2023 and at the time of GTC was available in limited quantities, it’s not referenced in this benchmark comparison. The Grace Blackwell GB200 is the newly announced product that is compared to H100 and isn’t likely to ship in volume until 2025. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval. They could have chosen to compare GB200 against GH200, but the numbers wouldn’t have been as impressive, and users aren’t familiar with GH200 yet, so it’s a reasonable approach.
The architecture differences between the generations are that the HGX H100 is a system that is configured with eight H100s and two Intel CPUs as an air-cooled rack mounted server connected using Infiniband. The NVIDIA branded version of this product is called DGX H100, other vendors incorporate the HGX H100 system in their own packaging, DGX and HGX should have the same performance, but the benchmarks refer to the more generic HGX. The package is 14" high, 8 rack units, so with sufficient airflow up to four of them could be configured in a standard rack. The NVIDIA benchmark document refers to each HGX H100 unit as a “rack” which gives the impression that it takes up more space than it does.
The GH200 pairs an ARM architecture Grace CPU with a slightly upgraded H200 GPU, that has the same compute capacity but has more and faster memory. Various benchmarks show improvements of 1.4x to 1.8x on a per GPU basis depending on how memory intensive the workload is. Up to 256 GH200 modules can be connected using a shared memory architecture rather than Infiniband. For a benchmark configuration of eight networked 8xH100+2xCPU vs a shared memory 64xGH200 cluster there is some speedup due to the lower overhead and higher speed of the memory interconnect, and the extra capacity of 64 Grace CPUs vs. 16 Intel CPUs.
The specifications for Blackwell are shown in the table below, this is the performance for a single water cooled GB200 module, which is two GPUs, and this confuses the issue somewhat. It’s important to be clear whether the reference is to a GB200 module or a single GPU from it, or the air cooled B100/B200. The GB200 module pairs one Grace CPU with two Blackwell GPUs rather than the GH200 that has one Hopper GPU, so on a per module basis there is a 2x factor to take into account. The Blackwell GPU is made up of two chiplets in one package that are similar in size and process to the H200, which was a small incremental improvement over H100.
Just from looking at the silicon, we would expect a single Blackwell GPU to be about twice the performance of a single H200 and a bit more than twice an H100.
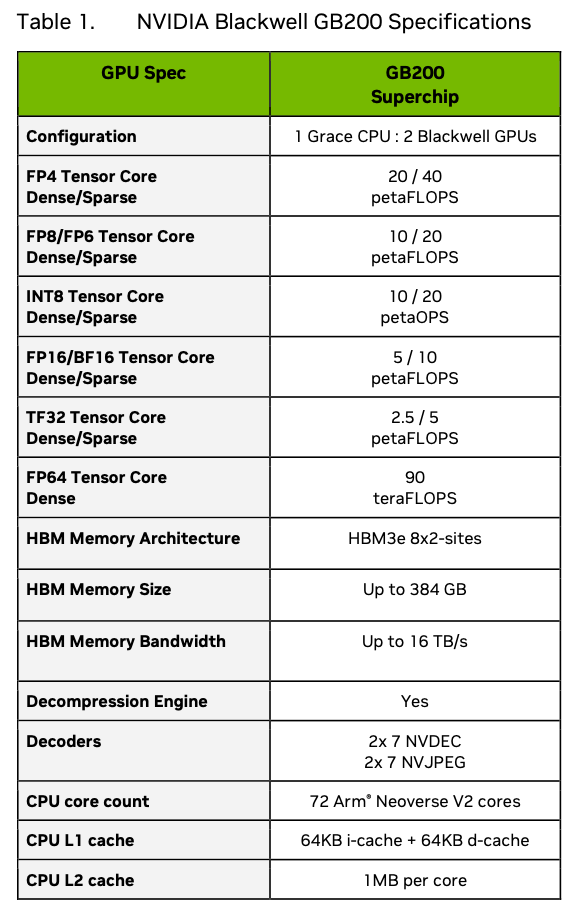
The HGX H100 8-GPU system is the baseline for comparison, and its datasheet performance is shown below.

On a per GPU FP8 sparse basis H100 is 32/8 = 4 Petaflops. Blackwell is 20/2 = 10 Petaflops, so the compute speedup is 2.5x, as expected. Memory bandwidth for H100 is 27/8 = 3.375TB/s, and Blackwell is 16/2 = 8TB/s, so the memory speedup is 2.37x. This is almost entirely what we would expect from the process and scale improvements between H100 and H200, then putting the equivalent of two H200 chiplets into a single Blackwell package. The extra memory bandwidth is needed to feed data to the increased compute performance.
The first benchmark claim is 4x for training performance vs. H100, rather than the 2.5x we would expect. The configuration is documented in the following figure.
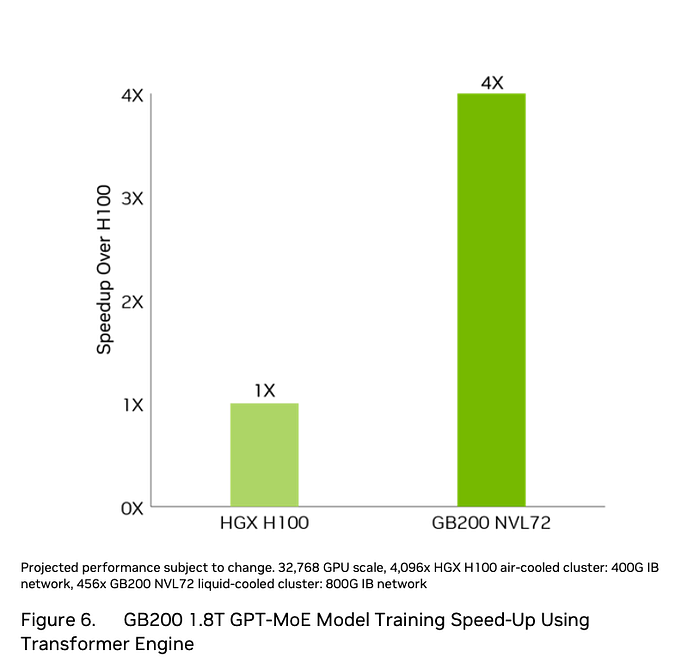
This benchmark is specified for the kind of configuration that OpenAI or Meta would use for training their biggest models. It consists of 32768 H100 GPUs configured as a network of 4096 HGX H100 machines (usually configured four per rack, this would be 1024 air-cooled racks), vs. 456 NVL72 water cooled racks containing 32832 Blackwell GPUs. The speedup we would expect is 2.5x, so there must be an additional 1.6x gain from the interconnect. The H100 interconnect is NVlink at 900GB/s of coherent shared memory bandwidth between 8 GPUs, then 4096 nodes connected by Infiniband at 400Gbit/s (less than 40GB/s because of 8bit in 10bit encoding and packet protocol overhead). The NVL72 has 72 GPUs connected via NVlink at 1800GB/s, then 456 nodes connected by Infiniband at 800Gbits/s (less than 80GB/s). The probability that a GPU to GPU transfer occurs over NVlink is nine times higher and transfers occur at twice the speed for NVL72. This is a reasonable explanation for the 1.6x extra speedup. This applies regardless of the precision used, as Blackwell is 2.5x faster than H100 for FP8, FP16 etc.
The over-all 4x training speedup claim seems plausible for large configurations. However comparing small configurations of between 1 and 8 GPUs the training speedup will be more like 2.5x.
The configuration that is referenced for the 30x inference benchmark is NVL-36, which takes up half the rack shown in the photo and contains 18 GB200 modules on nine boards, plus an unspecified number of NVlink memory switch boards.

There is also a footnote at the bottom of page 14 of the technical brief:
“Token-to-token latency (TTL) = 50ms real time, first token latency
(FTL) = 5s, input sequence length = 32,768, output sequence length = 1,028, 64 H100 GPUs air-cooled vs. 18 GB200 Superchips with NVL36 liquid-cooled, per GPU performance comparison. TCO, energy savings for 100 racks eight-way HGX H100 air-cooled vs. 1 rack GB200 NVL72 liquid-cooled with equivalent performance.”
For inference there is a new FP4 format in Blackwell that doubles the floating point operation capacity over the FP8 based H100, so we would expect the per GPU benchmark claim for GB200 to be five times H100 based on the raw compute difference (4 Petaflops of FP8 for H100 and 20 Petaflops of FP4 for Blackwell per GPU), however the claim is 30x for performance and 25x for power efficiency. The big question is: How do they get to the higher comparison numbers? There’s a missing factor of 6x for performance and 5x for power efficiency that needs to be accounted for.
The benchmark was performed on a 1.8Trillion parameter GPT-MoE-1.8T model although it’s not clear how the model was changed to use FP8 to run on H100 and FP4 to run on GB200. There needs to be at least 1.8Tbytes of memory as FP8 just to hold the model weights, and 900Gbytes of memory as FP4. The NVL-36 system has over 6TB of high bandwidth GPU memory and the eight H100 based systems have a total of about 5TB of GPU memory. Inference configurations are usually sized based on the memory needed to hold the model first, then configurations are replicated to provide the request capacity needed.
There are two differences that improve the results. The first effect is that the FP4 model weights are 4bits rather than 8bits, so they are half the size, and that means they load twice as fast, with better cache hit rates for the same number of model parameters. The other effect is that the H100 cluster is eight systems networked with Infiniband, while the GB200 cluster is a single shared memory system.
We previously saw that increased memory bandwith and capacity gave a 1.4x to 1.8x speedup between a single H100 and H200 GPU that have the same amount of raw compute.
The diagram below is taken from the GTC keynote, and appears to be the source of the 30x speedup claim.

However the choice of where to pick the difference between the two curves seems to be quite arbitrary to me, at the point where the H100 system performance has dropped off a lot. I added some lines to the plot to make it easier to estimate the values and came up with new differences.
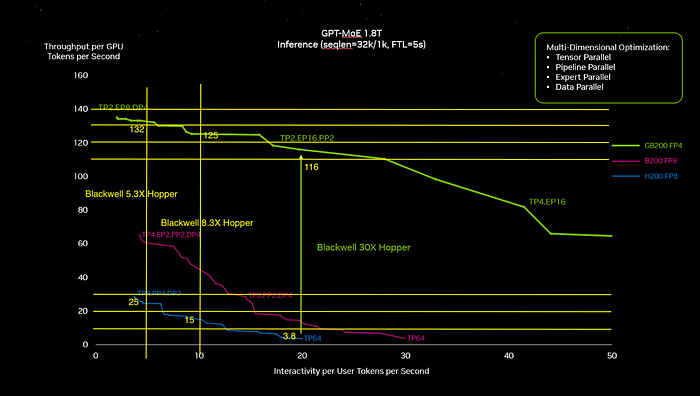
The comparisons I’ve labeled are 5.3x and 8.3x speedup from H100 to B200. These line up much better with what I’d expect from the hardware capabilities. The 30x figure appears to be comparing an H100 that is running quite inefficiently.
The 30x inference improvement claim was for the kind of inference models that OpenAI are running to operate ChatGPT. However I think people should expect more like 8–10x for inference on these large systems.
For small inference models that currently fit inside a single 8-GPU HGX100 and can use FP4, a speedup of around 5x would be expected on a GB200 based water cooled NVL-72 package. However there is also a more comparable air-cooled reduced clock rate version of the Blackwell GPU that comes in two 8-way versions, called the HGX B100 — designed to fit in the same power envelope as the HGX H100, and the HGX B200 that draws more power and runs at 90% of the per-GPU speed.
Air cooled 8-GPU package inference speedup over the older systems for HGX B100 is likely to be 4x, and HGX B200 4.5x, driven by the doubling of silicon area and move from FP8 to FP4.
The sustainability claim is that Total Cost of Operation (TCO) and energy use is 25x better. This is where the comparisons stop making sense. First, why is the TCO the same ratio as the Energy? If the cost of energy dominates TCO then there’s no point reporting the same number twice, but it doesn’t seem likely that the TCO of a large number of air cooled systems vs. a much smaller number of water cooled systems would just be proportional to the energy used.
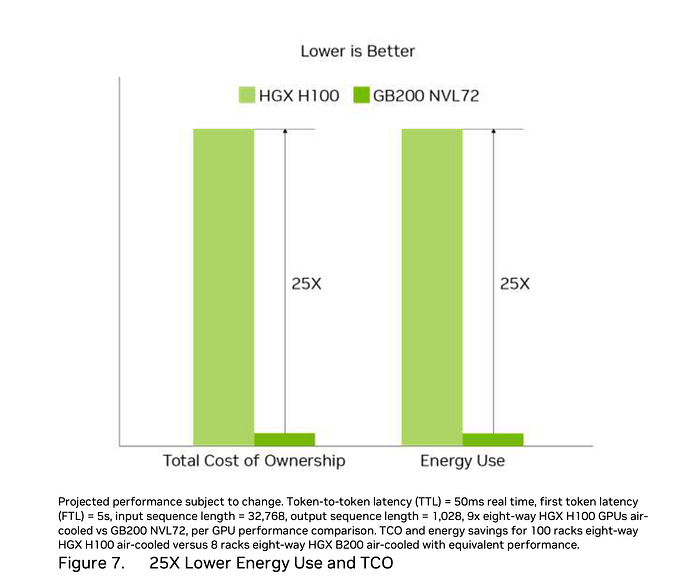
The comparison is 9x eight way = 72 H100 GPUs, vs. NVL72 which has 72 GB200 based GPUs, the NVIDIA claim is that this results in a 30x speedup and 1.2x higher total energy usage. The NVL72 is rated at 120 kW, so the nine HGX H100 would be 100 kW, so 11 kW each. Their spec rates them at 10.2 kW, so this part of the comparison makes sense.
The following details don’t make sense at all. 100 x HGX H100 = 800 GPUs and 1100 kW vs 8 x HGX B200 = 64 GPUs “with equivalent performance”.
I checked with NVIDIA and was told this is a typo and was given an updated comparison chart.
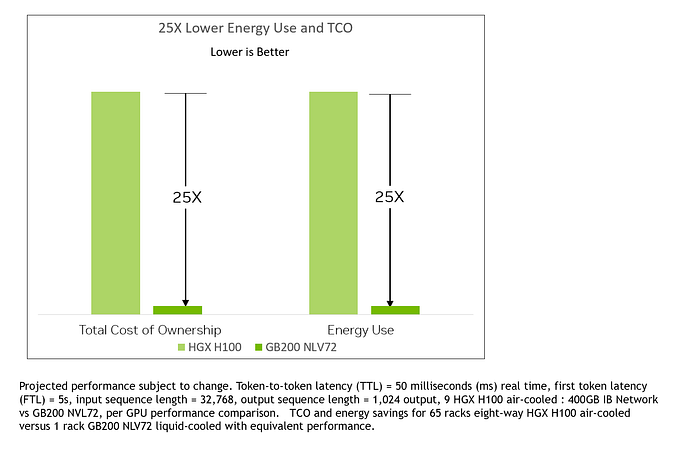
The comparison made in the updated note is that 65 x HGX H100’s = 520 GPUs and 700 kW, are equivalent performance to one NVL72 with 72 GPUs and 120 kW, which also makes no sense. The TCO calculations also make no sense to me.
Bottom line, the energy comparison benchmark only makes sense if we assume the basic comparison of 72 GPUs of each type, and ignore the additional notes. However if we take a more likely speedup of around 10x rather than 30x, then the energy comparison would come out at about 8x. This is still a very good improvement in inference efficiency.
There’s a more recent update to the NVIDIA roadmap that is summarized well at The Next Platform, the 25x improvement in energy claim persists there as a reduction from 10 joules/inference to 0.4 joules/inference. It’s not clear how they measure this, or if they just used the previous 25x claim to come up with a different metric. https://www.nextplatform.com/2024/06/02/nvidia-unfolds-gpu-interconnect-roadmaps-out-to-2027/
I’ve spent too long staring at the specs and trying to make sense of of this already. I suspect that there’s some additional confusion over the single GPU B200 module and the dual GPU GB200 module going on, as I’ve also seen NVIDIA claim that the B200 GPU is 15x the performance of the H100, which actually makes more sense, but doesn’t align with the GB200 per-GPU claims. If anyone has better ideas, please let me know!
[Update 9/28/2024] David Kanter pointed out some MLPerf inference results. H200 is about 1.4x H100 as expected, but a single Blackwell GPU is only 4x the H100 (as predicted above), not the 30x headline speed up. https://developer.nvidia.com/blog/nvidia-blackwell-platform-sets-new-llm-inference-records-in-mlperf-inference-v4-1/
