Platform Engineering Teams Done Right…

There’s been a lot of discussion about platforms recently, I talked about why I think it’s a current hot meme on the WTF Podcast with Charles Humble recently, and Sam Newman just wrote a blog post “Don’t call it a platform”.
What I want to cover in this blog post is how I think platforms should be structured, and why it’s always plural, there isn’t one platform or one platform team. We used this model effectively at Netflix when I was their cloud architect from 2010 through 2013.
There are three current underlying reasons for the platform engineering meme today. The first is that people have built complicated platforms on top of Kubernetes and there’s a market for tools to help do it better. The second is that some companies with tools to sell are marketing the term. The third is that the Team Topologies book defined how to create and manage Platform Teams so there’s interest in the terminology and definition.
However the concept is an old one, and I want to explain the principles and a model that I think works well for how to architect platforms in general.
The first principle I have is that it isn’t one platform, it’s layers of platforms that need different specialized knowledge so its usually many platform teams.
The second principle is that the platform layers are dynamic, evolve over time and tend to move “up the stack” as they add functionality, and shed capabilities that are subsumed by lower level platforms.
The third principle is that the interface to a platform should be driven by the users of the platform. A platform team should include a product manager, (or the team lead should perform that function) have a roadmap, and have mechanisms for prioritizing incoming requests
The fourth principle is that a very clear distinction should be made between building internal platforms optimized to change quickly to meet specific business needs, and building externalized platforms optimized for long term stability, where you may not know who or what depends on the platform, and can’t always ask them to change with you.
The layers of platforms start at the bottom with hardware choices such as which CPU architectures and vendors you want to use. The next layer is operating system platforms, what flavor of Linux, what version of Windows etc. The next layer is defined by the languages you want to use, Java, Python, Go, , Javascript, Rust etc, and the ecosystem of library functions you bought from a vendor or downloaded. These three layers all require very different expertise and are likely to be owned and configured by different teams.
The virtualization and networking platform could be datacenter based, with something like VMware, or cloud based using one of the cloud providers such as AWS EC2. Above that there’s a deployment platform such as Kubernetes or AWS Lambda. Back in the day, Netflix used the EC2 Autoscale Group as its primary deployment platform for “baked” Amazon Machine Images. The introduction of containers brought everyone a similar but lighter weight mechanism.
At this point we start to run into a problem with my fourth principle. You always want new functionality but if you depend on an outside supplier, they have to make it into a long term stable part of their platform. When we started with Netflix migration to cloud, we looked at platforms like Rightscale and decided not to use them. The main reason was that we didn’t want to pay for another supplier in the middle of our stack that would have incentives to maximize it’s value by making their platform fatter and more functional. We wanted AWS to grow its platform functionality, and to continually eat away at the bottom of the thin layer of rapidly evolving Netflix specific platform code that we had built. We cultivated our relationship with AWS to get them to (slowly) invest in platform features we needed, and AWS has also maintained excellent backward compatibility and stability for its interfaces.
If you are running a Kubernetes based platform you need a platform team and a bunch of tools to make it work well. However I would be thoughtful about the additional vendors and layering that vendor supplied tools bring. Every additional vendor adds management complexity, unexpected interactions and failure modes along with the functionality they are offering, and will evolve at their own slower pace, not the pace you would like. Open source tools which have an open development model that allows your team to make contributions may be a better approach. Netflix made many contributions to open source projects by it’s cloud platform team.
If you are running serverless with AWS Lambda, you’ve also bypassed the need for a platform team to run it, the serverless platform takes care of those concerns.
At Netflix we had an opinionated way of configuring AWS that was a company wide platform, for all AWS accounts, covering things like security and identity. However there were teams doing very different things on AWS, and they each built their own platform layer. We had the online personalization microservices platform that I’ve discussed a lot, there was a separate platform for data science, another one for movie encoding, and another for corporate IT. Each of those organizations had their own platform team. Then within online, different groups also built platforms that exposed their own set of business objects in exactly the right model to rapidly construct new functionality. The personalization team needed a different platform from the content delivery team or the security team, or the presentation layer team, sometimes with interfaces for different languages (Java, Python, C++, Javascript etc.).
I was thinking about drawing a layer cake diagram to show this but decided to put it on a Wardley Map instead (created using mapkeep.com).
Talking through the map, we start with an end user who can choose a web app or a mobile app. The web app depends on a web platform and associated development tooling, these seem to be a lot of work to maintain and change rapidly so you likely need some Javascript experts in a Web Platform Team. Mobile app platforms are much more standardized around iOS and Android, with Apple and Google providing the platform.
Both mobile and web front ends call an Application Program Interface (API) that is managed by an API proxy. Some people build custom API proxies, but I think it makes more sense to use one of the off the shelf options, with its own vendor based platform team. That calls into your custom business logic, which is written using a language and libraries platform, makes calls into web services and databases, and is built and deployed by a Continuous Integration/Continuous Deployment (CICD) pipeline. You probably need an in-house Developer Experience Platform Team that knows the languages, supports the libraries, and manages the web service and database vendors. This is one of the key teams that people have been talking about recently. I think it’s a different team with different expertise from the more infrastructure oriented Container Platform Team that provides a place for applications to run. I also advocate a Serverless First approach nowadays, where as much as possible is built using platforms like AWS Lambda — where there is no need for a platform team — and containers are used for things that have custom instance type requirements, very high continuous traffic, or long running computation. Some of the Kubernetes focused Container Platform Team vendors are selling solutions in this space, which I see as a separate team with different skills to the Developer Experience Platform Team.
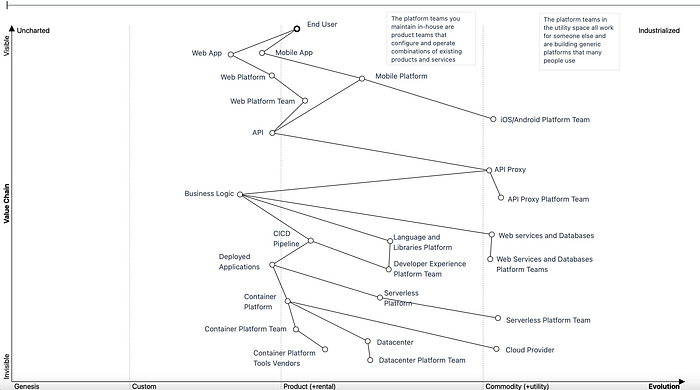
Here’s a public link to a copy of the map for people who would like to modify it. Note that mapkeep is in development and has a serverless backend that can have warmup issues, so if you see errors, wait a few seconds and try again.
Hopefully people find this interesting, and can use it to help come up with better justifications for their own combination of platform teams and tooling choices.
